上节学会了如何通过代码获取网页并通过BeautifulSoup进行简单的解析,这一节,我们将进一步学习BeautifulSoup对HTML更多的解析方法,通过查找标签的方法,标签组的使用,以及标签解析树的导航来定位我们想要的数据。
BeautifulSoup的find()和findAll()
1、函数介绍
借助这两个函数,你可以通过不同的标签、不同的属性轻松的过滤HTML页面,查找你心仪的它或他们(标签组或单个标签)。我们先看看这两个函数的定义:
findAll(tag,attributes,recursive,text,limit,keywords)
find(tag,attributes,recursive,text,keywords)
- 在绝大多数的情况下,我们只需要用tag和attributes两个函数。
– tag:你可以传一个标签或多个标签名称列表去做标签参数。
例如: findAll({“h1”,”h2”,”h3”,”h4”,”h6”}) 返回HTMl文档中所有标题标签的列表。
– attributes:是一个python字典封装一个标签的若干属性和对应的若干属性值。
例如: findAll(“span”,{“class”:{“green”,”red”}}) 返回HTML文档中span标签下class值是红色和绿色两种颜色的值 - recursive是一个布尔变量。如果为True,则查找tag参数的所有子标签,以及子标签的子标签;如果为False,就只查找文档的一级标签,默认为True。
- text是用标签的文本内容去匹配,而不是用标签的属性。
例如:findAll(text=”the prince”) 返回包含了“the prince”这个字符串的内容 - limit:是一个数字,如果你只获取结果中的前x个项。实际上,find就等价于findAll的limit等于1的情形。
- keyword:让你选择那些,具有指定属性及其指定值的标签
例如:findAll(id=’text’) 返回具有id这个属性,并且属性值为’text’的标签。
ps:findAll(id=’text’)等价于findAll(“”,{“id”:”text”}),实际我们更推荐第二种用法。
2、举例说明
我们举例一个网页http://www.pythonscraping.com/pages/warandpeace.html (任何时候,请在写代码前去查看你爬取页面的源码!!)。
这个页面小说任务对话内容都是红色,人物名称是绿色的。我们想要获取到这个网页中所有的人名。代码如下:1
2
3
4
5
6
7
8from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
bsObj = BeautifulSoup(html)
nameList = bsObj.findAll("span", {"class":"green"}) #获取span标签下所有绿色的内容
for name in nameList:
print(name)
此时输出结果如下图:
可以看出这个列表的输出还彪悍了标签,那么如果我们只想要里面的内容呢?
这时候如果把print(name)修改为print(name.get_text()),即可的到如下结果: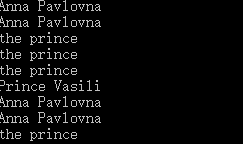
ps:但是要注意,不是任何时候都要用get_text()。因为他会把所有的标签都清楚,会把标签里的信息,包括超链接、段落等等都去除,所以要谨慎使用。
导航树
我们在上面讲到如何通过标签的名称和属性来查找标签。但是如果我们需要通过已知一个标签在文档中的位置来查找另一个标签呢?这就需要导航树。我们用虚拟的在线购物网站http://www.pythonscraping.com/pages/page3.html (答应我,先去看看这个网站和它的源码好吗?)。这个HTML页面可以映射成如下一棵树:
—— html
——body
——div.wrapper
——h1
——div.content
——table#giftList
——tr
——th
——th
——th
——th
——tr.gift#gift1
——td
——td
——span.excitingNote
——td
——td
——td
——img
——…其他表格行忽略…
——div.footer
1、子标签和后代标签
子标签就是父标签的下一级,而后代标签是指一个父标签下所有级别的标签。例如上面,tr是tabel的子标签,而tr、th、td、img、span等都是tabel的后代标签。于是可以得到,所有的子标签都是后代标签,但不是所有的后代标签都是子标签。
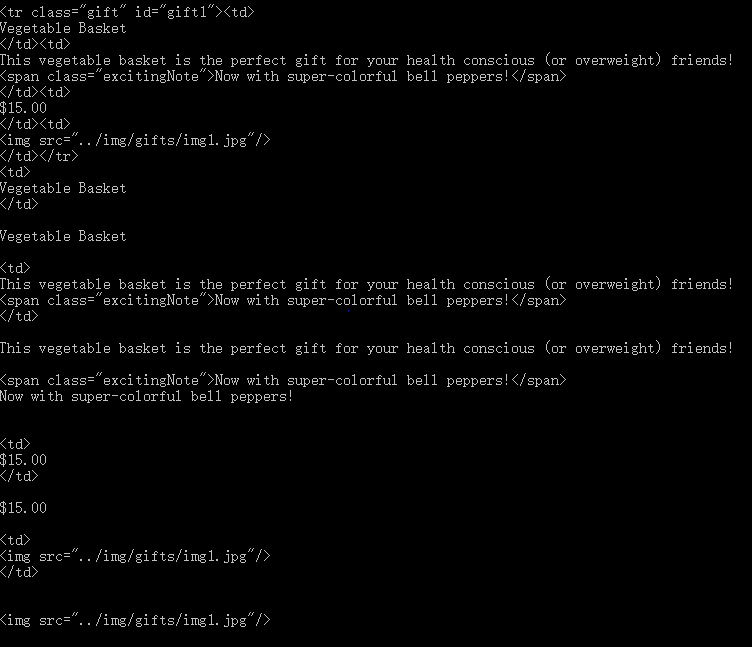
例如:如果你用children就会获取到表格中所有产品数据行标签。但如果你用descentdants就会有更多的标签。1
2
3
4
5
6
7
8from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html=urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj=BeautifulSoup(html)
for child in bsObj.find("table",{"id":"giftList"}).children:
print(child)
- bsObj.find(“table”,{“id”,”giftList”}).children;

- bsObj.find(“table”,{“id”,”giftList”}).descendants
2、兄弟标签
兄弟标签就是与你同级的标签就是你的兄弟标签,使用previous_sibling和next_sibling就可获取上一个或者下一个兄弟标签;使用previous_siblings和next_siblings可以获得一组兄弟标签,使用方法跟上面一样,这里不在赘述。效果可以自己试试。
3、父标签
父标签就是你的上一级标签,使用parent或者parents都有喜当爹的惊喜哦,请自己尝试。
正则表达式
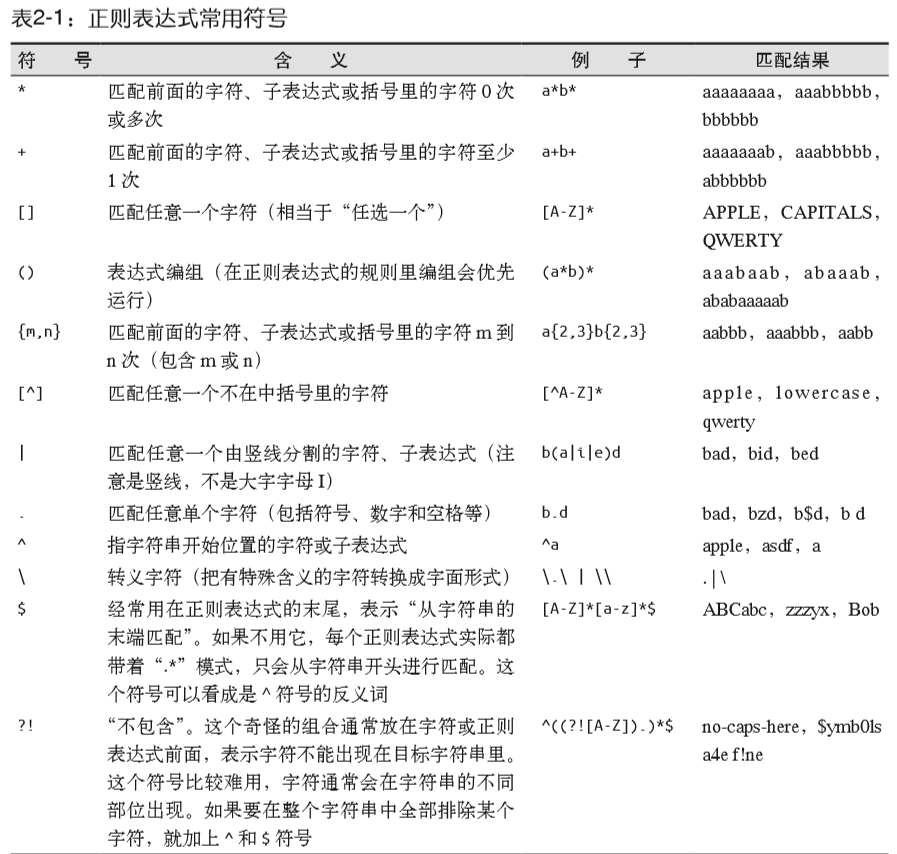
正则表达式就是用一系列符号标识某种通用的模式匹配。正则表达式的规则比较多,常用的符号也较多。附上表达式规则表和常用符号表:
在这里举一个使用正则表达式寻找上述例子界面中所有的图片路径:1
2
3
4
5
6
7
8
9
10from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html=urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj=BeautifulSoup(html)
images=bsObj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
for image in images:
print(image.attrs['src'])
获取属性
我们上面学习了如何获取和过滤标签(find()和findAll()),如何获取标签里的内容getText()。但是有时候可能我们不需要标签的内容,我们更想要查找标签的属性。比如标签’a’指向的URL链接就包含在href属性中,或者’img’标签的图片文件包含在src属性中。我们可以使用:
myTag.attrs获取myTag标签的所有属性,存成一个python字典对象。比如我要获取src属性。我就可以写成:
myImgTag.attrs[“src”]
该例子,在上面代码中有使用过。


